ETL(Extract,Transform,Load)
ETL就是抽取转换加载,是一个数据集成的过程,它是一个将来自多个数据源的数据组合到单一的,一致的数据存储中,然后再添加到数据仓库或者别的什么系统中的工具。
ETL基础概念
ETL五大模块分别是:数据抽取、数据清洗、库内转换、规则检查、数据加载。
数据抽取
- 确定数据源,需要确定从哪些源系统进行数据抽取
- 定义数据接口,对每个源文件及系统的每个字段进行详细说明
- 确定数据抽取的方法:是主动抽取还是由源系统推送?是增量抽取还是全量抽取?是按照每日抽取还是按照每月抽取?
数据清洗与转换
数据清洗
主要将不完整数据、错误数据、重复数据进行处理数据转换
空值处理:可捕获字段空值,进行加载或替换为其他含义数据,或数据分流问题库
数据标准:统一元数据、统一标准字段、统一字段类型定义
数据拆分:依据业务需求做数据拆分,如身份证号,拆分区划、出生日期、性别等
数据验证:时间规则、业务规则、自定义规则
数据替换:对于因业务因素,可实现无效数据、缺失数据的替换
数据关联:关联其他数据或数学,保障数据完整性
数据加载
将数据缓冲区的数据直接加载到数据库对应表中,如果是全量方式则采用 LOAD 方式,如果是增量则根据业务规则 MERGE 进数据库
AWS Glue
Glue提供ETL服务,由Glue Data Catalog(中央元数据存储库),ETL引擎,以及处理的作业系统
Data Catalog
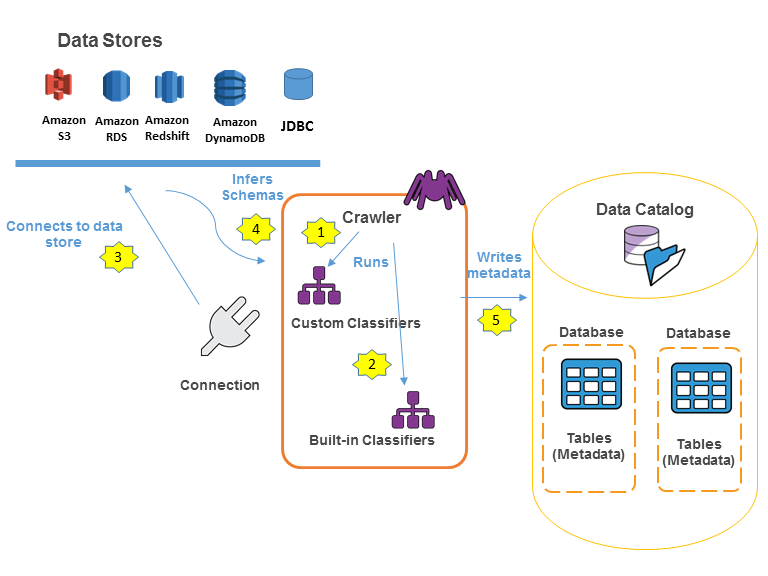
有时候会有从不同的数据源统一数据的需求,这时可能字段名不同,但是实际存的数据意义相同,这样需要对其进行统一,在glue中可以通过crawler+classifier实现。
存储了数据的位置、架构和运行时指标的索引,一般来说从不同的数据源爬取了程序之后,会通过Classifier对其进行分类,分类器检查给定文件的格式是否可以处理。如果可以处理,分类器将以与该数据格式匹配的对象的形式创建一个模式。
Classifier在爬虫任务的时候触发,通过爬虫+classifiers自动识别应该到哪个字段去,流程如下图。
AWS Lake Formation FindMatches
Glue内置了机器学习功能,可以通过 FindMatches 转换,可以识别数据集中的重复或匹配记录,即使记录没有公共唯一标识符且没有完全匹配的字段也是如此创建自定义转换来清理数据。