cpp随笔
CentOS7.6 安装g++ 11 和gcc 11
yum install centos-release-scl
yum list dev\*gcc //用于查看可以安装的版本
yum install devtoolset-11-gcc devtoolset-11-gcc-c++
source /opt/rh/devtoolset-11/enable
gcc -v
g++ -v
echo "source /opt/rh/devtoolset-11/enable" >> /etc/bashrc
source /etc/bashrc 智能指针
C++98/03 标准中,支持使用 auto_ptr 智能指针来实现堆内存的自动回收;C++11 新标准在废弃 auto_ptr 的同时,增添了 unique_ptr、shared_ptr 以及 weak_ptr 这 3 个智能指针来实现堆内存的自动回收。
C++ 智能指针底层是采用引用计数的方式实现的。
简单的理解,智能指针在申请堆内存空间的同时,会为其配备一个整形值(初始值为 1),每当有新对象使用此堆内存时,该整形值 +1;反之,每当使用此堆内存的对象被释放时,该整形值减 1。当堆空间对应的整形值为 0 时,即表明不再有对象使用它,该堆空间就会被释放掉。
shared_ptr\
shared_ptr\
std::shared_ptr<int> p1; //不传入任何实参
std::shared_ptr<int> p2(nullptr); //传入空指针 nullptr
std::shared_ptr<int> p3(new int(10));// 在构建 shared_ptr 智能指针,明确其指向。
std::shared_ptr<int> p3 = std::make_shared<int>(10);//C++11 标准中还提供了 std::make_shared<T> 模板函数,可以用于初始化 shared_ptr 智能指针
//调用拷贝构造函数
std::shared_ptr<int> p4(p3);//或者 std::shared_ptr<int> p4 = p3;
//调用移动构造函数
std::shared_ptr<int> p5(std::move(p4)); //或者 std::shared_ptr<int> p5 = std::move(p4);
&(*xxx_ptr\
std标准库
左值右值
简单意义上来说,左值就是等式左边的值,右值就是等式右边的值。
一般意义上来说,
左值是表达式结束后依然存在的持久对象(代表一个在内存中占有确定位置的对象)
右值是表达式结束时不再存在的临时对象(不在内存中占有确定位置的表达式)
便携方法:对表达式取地址,如果能,则为左值,否则为右值
无论左值引用类型的变量还是右值引用类型的变量,都是左值,因为它们有名字。
左值引用
int a = 10;
int &b = a; // 定义一个左值引用变量
b = 20; // 通过左值引用修改引用内存的值
// int &b = 10;是无法编译的,因为10是右值
const int &var = 10;//可以通过编译,因为这属于是常引用来引用常量数字10
//此刻内存上产生了临时变量保存了10,这个临时变量是可以进行取地址操作的,因此var引用的其实是这个临时变量左值引用在汇编层面其实和普通的指针是一样的;定义引用变量必须初始化,因为引用其实就是一个别名,需要告诉编译器定义的是谁的引用。
右值引用
int &&var = 10;右值引用用来绑定到右值,绑定到右值以后本来会被销毁的右值的生存期会延长至与绑定到它的右值引用的生存期。
在汇编层面右值引用做的事情和常引用是相同的,即产生临时量来存储常量。但是,唯一 一点的区别是,右值引用可以进行读写操作,而常引用只能进行读操作。
右值引用的存在并不是为了取代左值引用,而是充分利用右值(特别是临时对象)的构造来减少对象构造和析构操作以达到提高效率的目的。
std::move()
通过调用std::move函数来获得绑定到左值上的右值引用
#include <iostream>
#include <utility>
#include <vector>
#include <string>
int main()
{
std::string str = "Hello";
std::vector<std::string> v;
// uses the push_back(const T&) overload, which means
// we'll incur the cost of copying str
v.push_back(str);
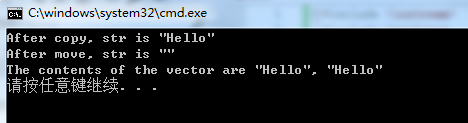
std::cout << "After copy, str is \"" << str << "\"\n";
// uses the rvalue reference push_back(T&&) overload,
// which means no strings will be copied; instead, the contents
// of str will be moved into the vector. This is less
// expensive, but also means str might now be empty.
v.push_back(std::move(str));
std::cout << "After move, str is \"" << str << "\"\n";
std::cout << "The contents of the vector are \"" << v[0]
<< "\", \"" << v[1] << "\"\n";
}move告诉编译器:我们有一个左值,但我们希望像一个右值一样处理它。我们必须认识到,调用move就意味着:除了对 str 赋值或销毁外,我们再使用它。在调用move之后,我们不能对moved-from对象(即str)做任何假设。
上述程序执行结果为
std::forward
完美转发
std::forward会将输入的参数原封不动地传递到下一个函数中,这个“原封不动”指的是,如果输入的参数是左值,那么传递给下一个函数的参数的也是左值;如果输入的参数是右值,那么传递给下一个函数的参数的也是右值。
原理
std::forward定义如下:
template<class _Ty>
_NODISCARD constexpr _Ty&& forward(remove_reference_t<_Ty>& _Arg) noexcept
{ // forward an lvalue as either an lvalue or an rvalue
return (static_cast<_Ty&&>(_Arg));
}
CData* Creator(T&& t)
{
return new CData(std::forward<T>(t));
}
12345678910- 如果T为
std::string&,那么std::forward<T>(t)返回值为std::string&&&, 折叠为std::string&,左值引用特性不变。 - 如果T为
std::string&&,那么std::forward<T>(t)返回值为std::string&&&&, 折叠为std::string&&,右值引用特性不变。 - 如果调用者为
std::string,调用将会转换成为std::string&,为类型1.
folly库
Facebook开源的基于C++14的库,在facebook内部广泛使用。Folly的全称为Facebook Open-source Library,目的不是为了替代标准库,而是对标准库的一种补充,尤其是大规模下的性能。
边记录接触到的组件
Futures
promise/future 是一个非常重要的异步编程模型,它可以让我们摆脱传统的回调陷阱,从而使用更加优雅、清晰的方式进行异步编程。c++11中已经开始支持std::future/std::promise,但是提供的future过于简单,而folly的实现中最大的改进就是可以为future添加回调函数(比如then)
回调函数
当程序跑起来时,一般情况下,应用程序(application program)会时常通过API调用库里所预先备好的函数。但是有些库函数(library function)却要求应用先传给它一个函数,好在合适的时候调用,以完成目标任务。这个被传入的、后又被调用的函数就称为回调函数(callback function)。
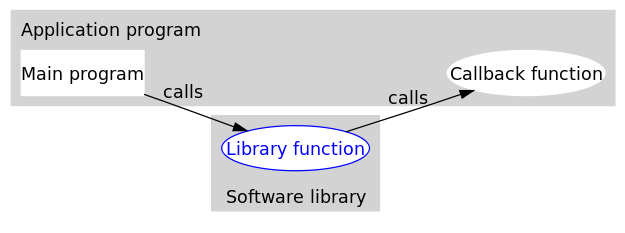
回调函数通常和应用处于同一抽象层(因为传入什么样的回调函数是在应用级别决定的)。而回调就成了一个高层调用底层,底层再回过头来调用高层的过程。
#include <folly/futures/Future.h>
using namespace folly;
using namespace std;
void foo(int x) {
// do something with x
cout << "foo(" << x << ")" << endl;
}
// ...
cout << "making Promise" << endl;
Promise<int> p;
Future<int> f = p.getFuture();
f.then(foo);
cout << "Future chain made" << endl;
// ... now perhaps in another event callback
cout << "fulfilling Promise" << endl;
p.setValue(42);
cout << "Promise fulfilled" << endl;代码非常简洁,首先定义一个Promise,然后从这个Promise获取它相关联的Future(通过getFuture接口),之后通过then为这个Future设置了一个回调函数foo,最后当为Promise赋值填充时(setValue),相关的Future就会变为ready状态(或者是completed状态),那么它相关的回调(这里为foo)会被执行。这段代码的打印结果如下:
making Promise
Future chain made
fulfilling Promise
foo(42)
Promise fulfilled虚函数和纯虚函数
定义一个函数为虚函数,不代表函数为不被实现的函数
定义他为虚函数是为了允许用基类的指针来调用子类的这个函数。
定义一个函数为纯虚函数,才代表函数没有被实现。
定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函数。
我们想要的是在程序中任意点可以根据所调用的对象类型来选择调用的函数,这种操作被称为动态链接,或后期绑定。
虚函数
class A
{
public:
virtual void foo()
{
cout<<"A::foo() is called"<<endl;
}
};
class B:public A
{
public:
void foo()
{
cout<<"B::foo() is called"<<endl;
}
};
int main(void)
{
A *a = new B();
a->foo(); // 在这里,a虽然是指向A的指针,但是被调用的函数(foo)却是B的!
return 0;
}虚函数它虚就虚在所谓”推迟联编”或者”动态联编”上,一个类函数的调用并不是在编译时刻被确定的,而是在运行时刻被确定的。由于编写代码的时候并不能确定被调用的是基类的函数还是哪个派生类的函数,所以被成为”虚”函数。
那什么是纯虚函数呢
纯虚函数
纯虚函数是在基类中声明的虚函数,它在基类中没有定义,但要求任何派生类都要定义自己的实现方法。在基类中实现纯虚函数的方法是在函数原型后加 =0:
virtual void funtion1()=0纯虚函数存在的意义
- 为了方便使用多态特性,我们常常需要在基类中定义虚拟函数。
- 在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理
为了解决上述问题,引入了纯虚函数的概念,将函数定义为纯虚函数(方法:virtual ReturnType Function()= 0;),则编译器要求在派生类中必须予以重写以实现多态性。同时含有纯虚拟函数的类称为抽象类,它不能生成对象。这样就很好地解决了上述两个问题。
声明了纯虚函数的类是一个抽象类。所以,用户不能创建类的实例,只能创建它的派生类的实例。
纯虚函数最显著的特征是:它们必须在继承类中重新声明函数(不要后面的=0,否则该派生类也不能实例化),而且它们在抽象类中往往没有定义。
定义纯虚函数的目的在于,使派生类仅仅只是继承函数的接口。
纯虚函数的意义,让所有的类对象(主要是派生类对象)都可以执行纯虚函数的动作,但类无法为纯虚函数提供一个合理的默认实现。所以类纯虚函数的声明就是在告诉子类的设计者,”你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。
类中至少有一个函数被声明为纯虚函数,则这个类就是抽象类。纯虚函数是通过在声明中使用 “= 0” 来指定的
<<<<<<< HEAD
读写文件
std::string getIp(){
ifstream infile; //读文件流
infile.open("ip.txt");
infile>>ipAddress;//读一行数据
infile.close();
}
void Send_ok(std::vector<KV> &kv){
ofstream outfile;//写文件流
outfile.open("out.txt");
for(auto it : kv){
outfile<<it.first<<"-----"<<it.second<<endl;//写一行数据
}
outfile<<"------------------------------------"<<endl;
outfile.close();
}读写IO流
- ofstream:该数据类型表示输出文件流,用于创建文件并向文件写入信息。
- ifstream:该数据类型表示输入文件流,用于从文件读取信息。
- fstream:该数据类型通常表示文件流,且同时具有 ofstream 和 ifstream 两种功能,这意味着它可以创建文件,向文件写入信息,从文件读取信息。
模式
- ios::app:追加模式。所有写入都追加到文件末尾。
- ios::ate:文件打开后定位到文件末尾。
- ios::in:打开文件用于读取。
- ios::out:打开文件用于写入。
- ios::trunc:如果该文件已经存在,其内容将在打开文件之前被截断,即把文件长度设为 0。
读文件
#include <fstream>
#include <iostream>
ifstream infile;
infile.open("/root/codetest/ip.txt");
infile>>destIpAddress;
infile>>selfIpAddress;
infile.close();
std::cout<<destIpAddress<<" "<<selfIpAddress<<endl;写文件
fstream outfile;
outfile.open("/root/codetest/out.txt",ios::out|ios::app);//追加
for(auto it : kv){
outfile<<it.first<<"-----"<<it.second<<endl;
}
outfile<<"------------------------------------"<<endl;
outfile.close();int string转换
sstring s = "12";
int a = atoi(s.c_str());
s = std::to_string(a);string 分割
string char*转换
string str="abc";
//char*p=(char*)str.data(); 都行
char *p=(char*)str.c_str();
string x = p;strtok()
char strtok(char str, const char *delim)
- str—要被分解的字符串
- delim—用作分隔符的字符(可以是一个,也可以是集合)
该函数返回被分解的第一个子字符串,若无可检索的字符串,则返回空指针
vector<string> split(const string& str, const string& delim) {
vector<string> res;
if("" == str) return res;
//先将要切割的字符串从string类型转换为char*类型
char * strs = new char[str.length() + 1] ; //不要忘了
strcpy(strs, str.c_str());
char * d = new char[delim.length() + 1];
strcpy(d, delim.c_str());
char *p = strtok(strs, d);
while(p) {
string s = p; //分割得到的字符串转换为string类型
res.push_back(s); //存入结果数组
p = strtok(NULL, d);
}
return res;
}
#ifdef #ifndef
#ifndef和#ifdef都是一种宏定义判断,作用是防止多重定义。
使用格式如下:
#ifdef 标识符
程序段1
#else
程序段2
#endif
一般的使用场景如下:
- 头文件中使用,防止头文件被多重调用
- 作为测试使用,省去注释代码的麻烦
- 作为不同角色或者场景的判断使用
#include <iostream>
#include "A.h"
#define INIT_B
using namespace std;
B::B()
{
#ifdef INIT_B
this->b=200;
#endif
}
//有时候当代码比较多的时候,要做测试,但是全部注释很麻烦,这时候使用#ifdef非常好用,如果我不想执行
//this->b=200;这段程序,只需要将上面的#define INIT_B注释就可以了。static_cast、reinterpret_cast、const_cast、dynamic_cast
C++ 引入了四种功能不同的强制类型转换运算符以进行强制类型转换主要为了克服C语言强制类型转换的以下三个缺点
没有从形式上体现转换功能和风险的不同。
例如,将 int 强制转换成 double 是没有风险的,而将常量指针转换成非常量指针,将基类指针转换成派生类指针都是高风险的,而且后两者带来的风险不同(即可能引发不同种类的错误),C语言的强制类型转换形式对这些不同并不加以区分。
将多态基类指针转换成派生类指针时不检查安全性,即无法判断转换后的指针是否确实指向一个派生类对象。
难以在程序中寻找到底什么地方进行了强制类型转换。
用法
强制类型转换运算符 <要转换到的类型> (待转换的表达式)
static_cast
static_cast 用于进行比较“自然”和低风险的转换,如整型和浮点型、字符型之间的互相转换如果对象所属的类重载了强制类型转换运算符 T(如 T 是 int、int* 或其他类型名),则 static_cast 也能用来进行对象到 T 类型的转换。
static_cast 不能用于在不同类型的指针之间互相转换,也不能用于整型和指针之间的互相转换,当然也不能用于不同类型的引用之间的转换。因为这些属于风险比较高的转换。
#include <iostream>
using namespace std;
class A
{
public:
operator int() { return 1; }
operator char*() { return NULL; }
};
int main()
{
A a;
int n;
char* p = "New Dragon Inn";
n = static_cast <int> (3.14); // n 的值变为 3
n = static_cast <int> (a); //调用 a.operator int,n 的值变为 1
p = static_cast <char*> (a); //调用 a.operator char*,p 的值变为 NULL
n = static_cast <int> (p); //编译错误,static_cast不能将指针转换成整型
p = static_cast <char*> (n); //编译错误,static_cast 不能将整型转换成指针
return 0;
}reinterpret_cast
reinterpret_cast 用于进行各种不同类型的指针之间、不同类型的引用之间以及指针和能容纳指针的整数类型之间的转换。转换时,执行的是逐个比特复制的操作。这种转换提供了很强的灵活性,但转换的安全性只能由程序员的细心来保证了。
#include <iostream>
using namespace std;
class A
{
public:
int i;
int j;
A(int n):i(n),j(n) { }
};
int main()
{
A a(100);
int &r = reinterpret_cast<int&>(a); //强行让 r 引用 a
r = 200; //把 a.i 变成了 200
cout << a.i << "," << a.j << endl; // 输出 200,100
int n = 300;
A *pa = reinterpret_cast<A*> ( & n); //强行让 pa 指向 n
pa->i = 400; // n 变成 400
pa->j = 500; //此条语句不安全,很可能导致程序崩溃
cout << n << endl; // 输出 400
long long la = 0x12345678abcdLL;
pa = reinterpret_cast<A*>(la); //la太长,只取低32位0x5678abcd拷贝给pa
unsigned int u = reinterpret_cast<unsigned int>(pa);//pa逐个比特拷贝到u
cout << hex << u << endl; //输出 5678abcd
typedef void (* PF1) (int);
typedef int (* PF2) (int,char *);
PF1 pf1; PF2 pf2;
pf2 = reinterpret_cast<PF2>(pf1); //两个不同类型的函数指针之间可以互相转换
}第 19 行的代码不安全,因为在编译器看来,pa->j 的存放位置就是 n 后面的 4 个字节。 本条语句会向这 4 个字节中写入 500。但这 4 个字节不知道是用来存放什么的,贸然向其中写入可能会导致程序错误甚至崩溃。
const_cast
const_cast 运算符仅用于进行去除 const 属性的转换,它也是四个强制类型转换运算符中唯一能够去除 const 属性的运算符。
将 const 引用转换为同类型的非 const 引用,将 const 指针转换为同类型的非 const 指针时可以使用 const_cast 运算符
const string s = "Inception";
string& p = const_cast <string&> (s);
string* ps = const_cast <string*> (&s); // &s 的类型是 const string*dynamic_cast
用 reinterpret_cast 可以将多态基类(包含虚函数的基类)的指针强制转换为派生类的指针,但是这种转换不检查安全性,即不检查转换后的指针是否确实指向一个派生类对象。dynamic_cast专门用于将多态基类的指针或引用强制转换为派生类的指针或引用,而且能够检查转换的安全性。对于不安全的指针转换,转换结果返回 NULL 指针。
dynamic_cast 是通过“运行时类型检查”来保证安全性的。dynamic_cast 不能用于将非多态基类的指针或引用强制转换为派生类的指针或引用——这种转换没法保证安全性,只好用 reinterpret_cast 来完成。
#include <iostream>
#include <string>
using namespace std;
class Base
{ //有虚函数,因此是多态基类
public:
virtual ~Base() {}
};
class Derived : public Base { };
int main()
{
Base b;
Derived d;
Derived* pd;
pd = reinterpret_cast <Derived*> (&b);
if (pd == NULL)
//此处pd不会为 NULL。reinterpret_cast不检查安全性,总是进行转换
cout << "unsafe reinterpret_cast" << endl; //不会执行
pd = dynamic_cast <Derived*> (&b);
if (pd == NULL) //结果会是NULL,因为 &b 不指向派生类对象,此转换不安全
cout << "unsafe dynamic_cast1" << endl; //会执行
pd = dynamic_cast <Derived*> (&d); //安全的转换
if (pd == NULL) //此处 pd 不会为 NULL
cout << "unsafe dynamic_cast2" << endl; //不会执行
return 0;
}第 20 行,通过判断 pd 的值是否为 NULL,就能知道第 19 行进行的转换是否是安全的。第 23 行同理。